
Scraping Unstructured Content
Overview
Indexing information from a structured source such as a ecommerce platform, CMS or database is a common process which is well documented in this developer portal. There are many cases however, where critical data resides in unstructured formats and must be "scraped." This process is described below.
Diagram
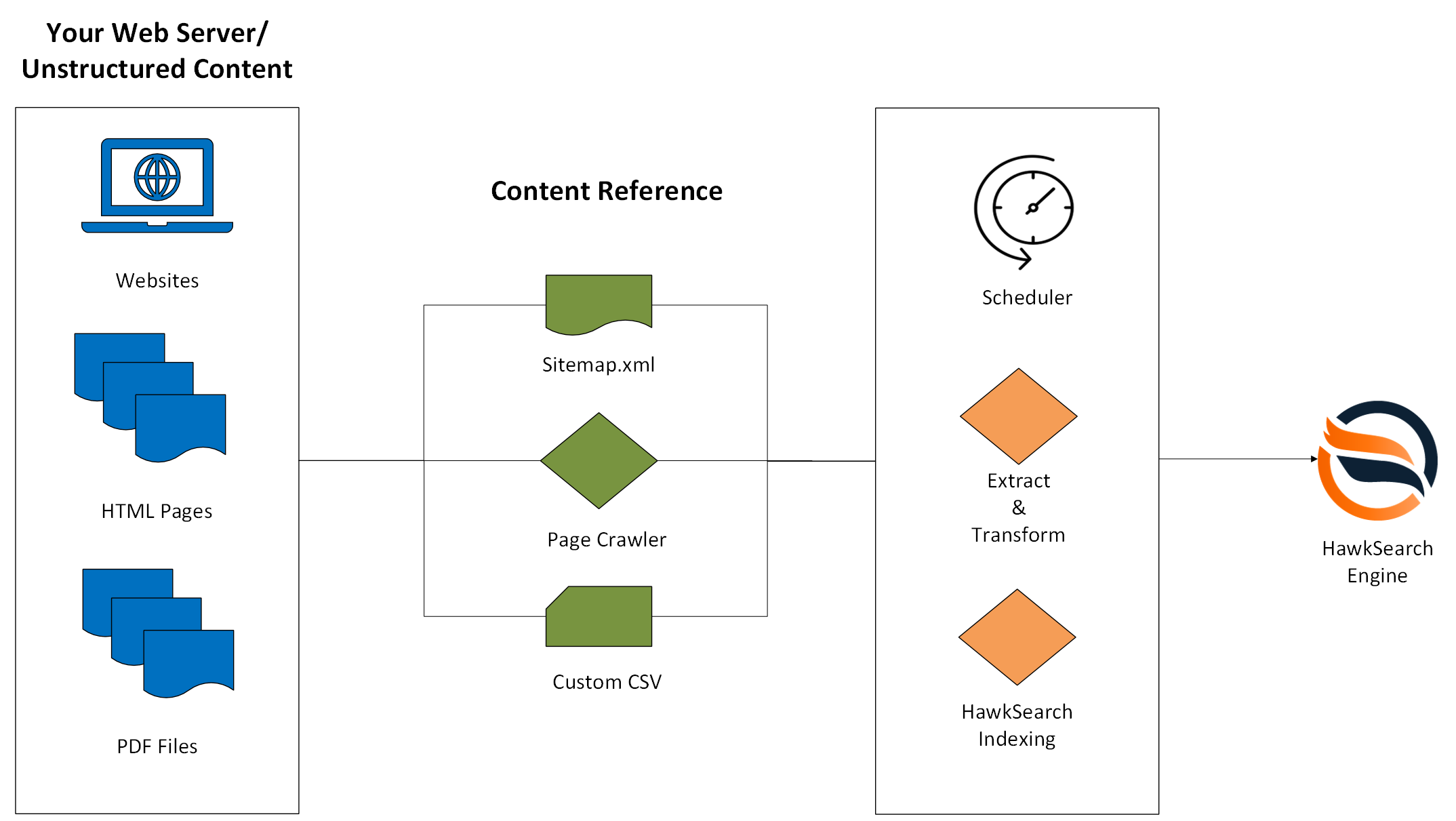
Your Unstructured Content
This critical information is most likely residing on a web server and residing on a website, is captured in HTML files within some directories or is within PDF files. Since this information is on a web server, it means that an external process from HawkSearch can access these files through a URL. This may not always be the case and if so, please reach out to HawkSearch to discuss options.
Content Reference
Since the unstructured content can be accessed through an online process, there are three ways that HawkSearch can know where those files are and scrape their contents.
Sitemap.xml Option
Most websites have a sitemap.xml file that tells crawlers or spiders which files should be included. This is a preferred method for HawkSearch as well because perhaps not all files on your web server should be scraped for this indexing process. However, if this is not available, there are other options to consider.
Page Crawler Option
If a sitemap.xml file is not available, HawkSearch offers a page crawler that will traverse all of the links within pages of your site. This is often referred to as "spidering a site." This process can be modified to avoid specific files or directories based on business need.
Custom CSV
In some cases, it may be possible to create a CSV with the URL of all of the pages to be indexed into HawkSearch. If this option is available and additional metadata can be provided, this could help with the next "Extract and Transform" phase described below.
Indexing
This is the point the whole process has been working towards - leveraging the HawkSearch Indexing API to take the extracted data discussed above and "loading" or indexing it to your engine. This process uses the same Indexing API that is described in this developer portal.
HawkSearch Engine
The goal of this whole process is to get the data out of the unstructured files in your environment into the HawkSearch engine. From this point, your team can configure all of the merchandising rules that drive the value of the HawkSearch solution.