

Developer Best Practices
There are a number of best practices developers should be aware of when building out a Hawksearch Implementation. Below are a number of key best practices. Please contact hawksearch support for additional information and guidance on managing your implementations.
Getting Started
What are the first steps to configuring your Hawksearch engine? This guides you through the most important field settings to get your engine up and going quickly.
Review Field Configuration
Below are important parts of the field configuration that should be addressed. After making changes to the fields, a full index must be rebuilt in order to see the changes.
Mark Fields to be Queried

Know what fields you have in your Hawksearch engine and set some to be queried. Be thoughtful about which fields have the query flag turned on. Fields that are commonly queried for searches:
Product Name/Article Title
Department/Category
Part Number
Brand/Manufacturer
Description fields on products can often return irrelevant results due to the excess words used.
Looking at the example data below, if the description field is queried, this flashlight would be returned for searches on keywords like: tent, camping, AAA batteries, brite white, white. In this case, we would not recommend the description field to be queried.
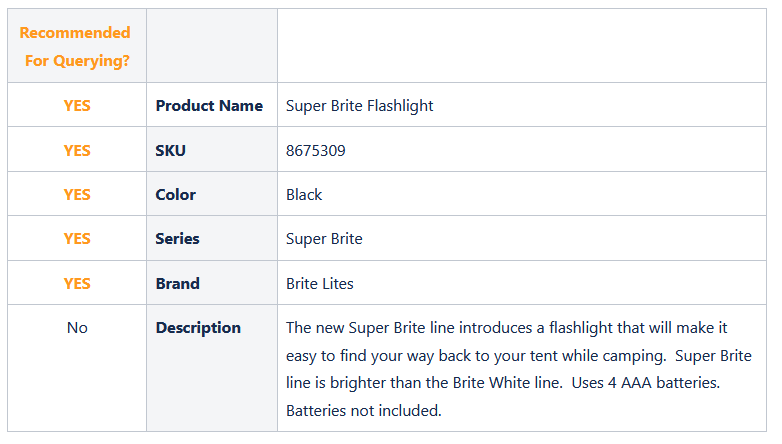
Mark Fields for Dictionary

For correcting typos and misspellings, turn the dictionary flag on for fields that should contribute to the dictionary. When the index is built, a custom dictionary is created. The data in the dictionary comes from the fields where this flag is turned on. It is not usually desirable to turn on the dictionary flag for an id field, like SKU.
If phrase corrections would make sense, turn on the phrase flag for the fields that the dictionary should take phrases from. This is recommended for fields like name, brand or category. This setting will allow the Autocorrect and Did You Mean functionality to offer phrases to the user.
Indexing
Creating an Index
If more than one developer creates an index at the same time, there is a risk that one of the indexes will not be created. As Hawksearch currently provides two index slots for dev environment there is a risk that one or more indexes will not be created.
Reindexing an Index
If more than one developer reindex at the same time, there is a risk that one of the indexes will not be created. Hawksearch currently provides two index slots in the dev environment, and if more than two indexes are created during reindexing, there is a risk that one or more indexes will not be created.
Deleting an Index
If more than one developer is working on the same engine, deleting of the indexes should be collaborated with others, because of data lost.
Index Mapping
Using index mapping provided from the Hawksearch admin page -> Index Mappings more than one developer can use a single index. Developers need to know that if an index is re-indexed, a new index will be created on the engine and all developers who are mapped to this index will not be able to use it due to the difference in the name of the index. In this case, the mapping needs to be updated.
Setting a Current Index
Since there are no direct problems with the existence of the current index, there are things to keep in mind:
Index set as current cannot be deleted. You cannot delete the current index, you can only swap it. You can set current index from Hawksearch admin page -> Hawksearch Indexes
Index set as current cannot be re-indexed. If you try to reindex an index that is set to current, a new index will be created with the same suffix but with a different stamp. If the creation of the new index exceeds the maximum number of indexes (2 for development), the new index will not be created and the reindexing will fail.
Once set the current index cannot be undone. There will always be an index set as current in the respective engine.
Field & Facet Setup
Field and facet configuration impacts index size and payload size, which has an impact on indexing time and engine performance. The following guidelines are standard best practices, your configurations may vary depending on your data, business requirements and use cases.
Data Configuration: Fields
The following screenshot depicts the configuration settings within the field section that this document will cover. Below are some of the key field settings that impact index and payload size.
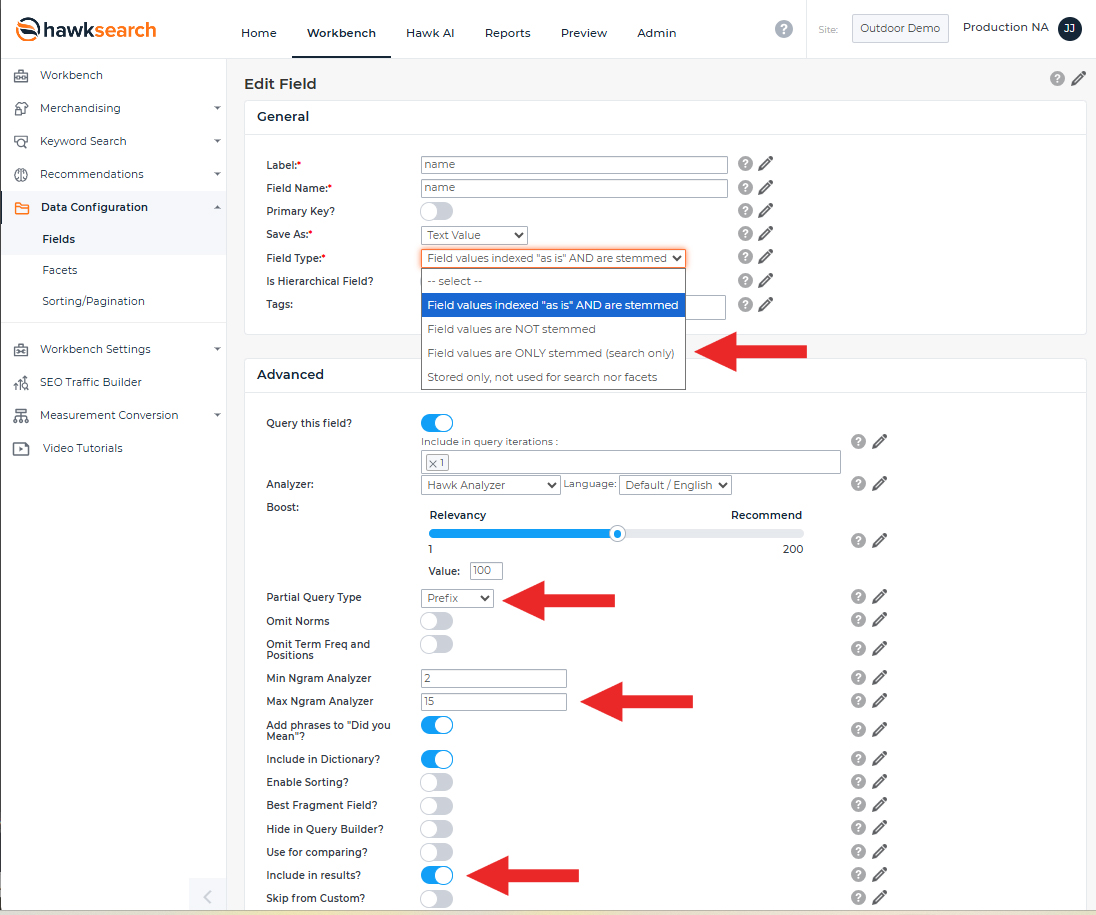
Field Type
There are four different configuration options for field type. This field configuration depends on the type of data that is included in the field.
- Field Values are NOT stemmed
This field configuration should be used in the following instances:
Fields that are used as Facets
Fields that are used for Sorting
Fields that need to be searched as is (i.e. on the full field)
Brand (e.g. “Under Armour” should match the full term. Searching “under” should not return a match on “Under Armour”)
Size fields
Numeric Values
- Field values are ONLY stemmed (search only)
This field configuration should be used in the following instances:
Searching words within a field (e.g. searching “Under Armour” would find a match for “Under Armour”, but searching “under” would also find a match on “Under Armour”)
Fields are NOT used for Sorting or Facets
Fields this setting is typically used on include:
Short Description
Content
- Field Values indexed “as is” AND are stemmed
This setting is a combination of the two settings above and this field configuration should be used in the following instances:
If the field will be used for Sorting or Facets AND for searching
This setting will store multiple versions of the field.
NOTE: while this option covers all scenarios, please use this setting judiciously as it will increase the index size to account for both ‘as is’ and stemmed values.
- Stored only, not used for search or facets
This field configuration should be used in the following instances:
This option should be used for fields that are not searchable or used as facets, but the field should be included in the response to render the layout
This setting is typically for fields such as:
Images Fields
URL Fields
Prefixed/Wildcard Fields
This field configuration should be used in the following instances:
Should only be set if prefix or wildcard querying is needed on front end or backend.
Please use this setting judiciously as it will increase the index size to account for all of the combinations being indexed.
Should not be used on long fields
This field setting will bloat the index if used incorrectly and negatively impact relevancy.
Typically this setting is not enabled on many fields, if at all.
Remember: Stemming handles searching words within a phrase, as well as variations of the word.
Wildcard will handle partial searches within a single value. The most common use for this setting is with fields such as:
SKU
UPC
Include in Results
Hawksearch stores both tokenized and pure text versions of the field. Turning this off stops storing the text version of the field, which in turn reduces the Index Size
This setting should only be enabled on fields that need the output for the field to render the item.
Data Configuration: Facets
The number of facets and the number of facet values has a direct relationship with the response time of your engine. This is due to a number of factors such as
Serializing the payload
Cardinality between all the facet values is a heavy operation
Facet Best Practices
Limit number of values within a facet to under 200
Define Coverage
Utilize Facet Overrides on Landing Pages
NOTE: In some unique instances, when there are an extreme number of facets configured in the workbench this can increase the response times. If Hawksearch sees this as an issue, we will call this out during your implementation phase.
Other Options for Reducing Payload Size
Payload size is directly related to the Field and Facet Optimization previously discussed.
Other options for reducing payload size include:
Limiting the number of products on the page
Utilize pagination or lazy loading
Types of Analyzers
This section outlines the available analyzers. There are five analyzer options that are available for the business user to select. The selection of an analyzer will override the default indexing configuration “Hawk Analyzer”. Each analyzer is explained below.
Hawk Analyzer **
The Hawk Analyzer has the same properties as the Snowball Analyzer (see below) but will take into account synonyms configured in the Hawksearch workbench. This is the default analyzer applied when the field is set to be queried.
Snowball Analyzer**
The stemming step converts a word into its stem. For example, if the word “climbing” is entered, the analyzer would convert the word to “climb” and use that to search a field with the Snowball Analyzer set on it. It would return items that contained climber, climbing, and climb. It is possible that information can be lost describing the original form of your text. For example, the terms universe, university and universal all stem to the same root, “univers” and would all return the same results. This is likely not be the desired result.
Description:
Stemming is applied
Stop words are removed
Colons, #, %, $, parentheses, and slashes are removed
Removes underscores, hyphens, @, and & symbols unless they are part of words or numbers
Remove apostrophe if it is (a) at the beginning of a word, (b) at the end of a word, or (c) followed by the letter s
Separates numbers from text when numbers are at the beginning of a word
Letter characters are converted to lowercase
Best Used For:
Fields that have content consisting of multiple versions of a word.
Standard Analyzer
The Standard Analyzer accounts for the following:
Description:
Separates text “smartly”, accounting for the following lexical types
alphanumerics
acronyms
company names
email addresses
computer hostnames
numbers
words with an interior apostrophe
serial numbers
IP addresses
Chinese and Japanese characters
Stop words are removed
Letter characters are converted to lowercase
No stemming applied
Best Used For:
Searching English words such as units of measure as well as fields with the values listed above.
Simple Analyzer**
The Simple Analyzer accounts for the following:
Description:
Separates text at non-letter characters and removes all non-letter characters
Letter characters are converted to lowercase
No stop words are removed
No stemming applied
Best Used For:
Fields that only have alphabetical characters and don’t need the advanced interpretation of the Standard Analyzer. For example, consider a field that stores famous 1-line quotes that will be queried. If a user searches “to be, or not to be” removing the standard stop words would leave nothing to search on. Additionally, if stemming were applied to this field, the results would not be as relevant as they would be without stemming. In a case like this, the Simple Analyzer makes a good choice.
Stop Analyzer
The Stop Analyzer accounts for the following:
Description:
Stop words are removed
Divides text at non-letter characters and removes all non-letter characters
Letter characters are converted to lowercase
No stemming applied
Best Used For:
When a simple, text-only analyzer is needed that also removes stop words. This should be used on fields that are intended to only have values made up of alphabetic characters.
Example:
Stop word: with
Original Product Name: Men's Long Mesh Short With Pockets
Product name with Stop Analyzer implemented: men s long mesh short pockets
White Space Analyzer
The White Space Analyzer accounts for the following:
Description:
Search terms divided at whitespace
No characters are removed
No characters are converted to lowercase
No stop words are removed
No stemming applied
Best Practices to rebuild index
Some best practices before sending an index rebuild request
- When sending a new index rebuild request, it is always a good idea to check if the previous request has finished processing. To check this, send a GET request to the URL https://dev.hawksearch.net/api/v10/index/status with the additional header parameter X-HawkSearch-ApiKey: YOUR_API_KEY
curl --location --request GET '<https://dev.hawksearch.net/api/v10/index/status>' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'X-HawkSearch-ApiKey: YOUR_API_KEY'
The status can be considered incomplete if it is one of these cases - New, Pending, Processing, Queue so please wait before sending another index rebuild request. If a new index rebuild request is sent while the current task isn’t complete, the new request is marked “duplicate” without being processed.
The status can be considered as done if it is one of these cases - Success, Error, Duplicated, Suspended in which case the new/updated index will be usable and further requests to rebuild are accepted.
{
"Status": "queue",
"Count": 0,
"Duration": "00:00:00",
"StartDateTime": "03-25-2021",
"EndDateTime": null,
"TimeZone": "Central Standard Time"
}
The status of a specific NotificationId can also be by appending the value of the NotificationId to the above request https://dev.hawksearch.net/api/v10/index/status/{{NotificationId}}
Updated 7 months ago